
启动hadoop所有进程的命令是A.start-dfs.shB.start-hadoop.shC.start-all.shD.start-hdfs.sh
题目
启动hadoop所有进程的命令是
A.start-dfs.sh
B.start-hadoop.sh
C.start-all.sh
D.start-hdfs.sh
相似考题
更多“启动hadoop所有进程的命令是”相关问题
-
第1题:
Hadoop环境变量中的HADOOP_HEAPSIZE用于设置所有Hadoop守护线程的内存。它默认是200GB。( )此题为判断题(对,错)。
正确答案:错误
-
第2题:
在Linux系统中,采用( )命令查看进程输出的信息,得到下图所示的结果。系统启动时最先运行的进程是( ),下列关于进程xinetd的说法中正确的是(请作答此空)。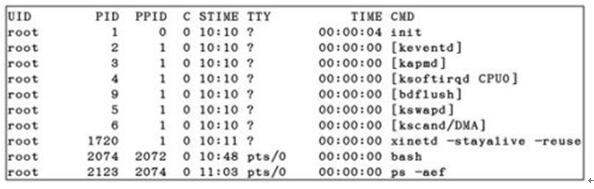 A.xinetd是网络服务的守护进程
A.xinetd是网络服务的守护进程
B.xinetd是定时服务的守护进程
C.xinetd进程负责配置网络接口
D.xinetd进程进程负责启动网卡答案:A解析:ps命令显示系统正在运行的进程,参数:e列出系统所有的进程,f列出详细清单。显示各列为:★ UID:运行进程的用户★ PID:进程的ID★ PPID:父进程的ID★ C:进程的CPU使用情况(进程使用占CPU时间的百分比)★ STIME:开始时间★ TTY:运行此进程的终端或控制台★ TIME:消耗CPU的时间总量★ CMD:产生进程的命令名称Linux操作系统内核被加载入内存后,开始掌握控制权。接着,它将完成对外围设备的检测,并加载相应的驱动程序,如软驱、硬盘、光驱等。然后,系统内核调度系统的第一个进程,init进程。作为系统的第一个进程,init的进程ID(PID)为1。它将完成系统的初始化工作,并维护系统的各种运行级别,包括系统的初始化、系统结束、单用户运行模式和多用户运行模式。在Linux系统中,大部分的服务进程(daemon)都会设置成在系统启动时自动执行。服务进程是指在系统中持续执行的进程。但是,过多进程同时执行必然会占据更多的内存、CPU时间等资源,从而使系统性能下降。为了解决这个问题,Linux系统提供了一个超级服务进程:inetd/xinetd。inetd/xinetd总管网络服务,使需要的程序在适当时候执行。当客户端没有请求时,服务进程不执行;只有当接收到客户端的某种服务器请求时,inetd/xinetd根据其提供的信息去启动相应的服务进程提供服务。inetd/xinetd负责监听传输层协议定义的网络端口。当数据包通过网络传送到服务器时,inetd/xinetd根据接收数据包的端口判断是哪个功能的数据包,然后调用相应的服务进程进行处理。 除Red Hat Linux 7使用xinetd来提供这个服务外,大部分版本的Linux系统都使用inetd。
-
第3题:
hadoop和spark的都是并行计算,两者都是用mr模型来进行并行计算,hadoop的一个作业称为job,job里面分为maptask和reducetask,每个task都是在自己的进程中运行的,当task结束时,进程也会结束
正确答案:错误 -
第4题:
hadoop和spark的都是并行计算,两者都是用mr模型来进行并行计算,hadoop的一个作业称为job,job里面分为map?task和reduce?task,每个task都是在自己的进程中运行的,当task结束时,进程也会结束
正确答案:错误 -
第5题:
关于IGWB服务器端进程启动描述错误的是()。
- A、操作系统启动后,PWD服务也随之启动
- B、PWD服务启动双机进程
- C、KERNEL进程启动双机进程
- D、KERNEL进程依次启动操作维护进程和接入点进程
正确答案:C -
第6题:
启动进程有手动启动和调度启动两种方法,其中调度启动常用的命令为at、batch和()。
正确答案:crontab -
第7题:
显示指定用户所启动的进程的命令是()。
- A、ps-x
- B、ps-u
- C、ps-g
- D、以上都不是
正确答案:B -
第8题:
填空题启动进程有手动启动和调度启动两种方法,其中调度启动常用的命令为at、batch和()。正确答案: crontab解析: 暂无解析 -
第9题:
单选题在ps命令什么参数是用来显示所有用户的进程的()。Ax
Bb
Cu
Da
正确答案: D解析: 暂无解析 -
第10题:
单选题从后台启动进程,应在命令的结尾加上符号()?A&
B@
C#
D$
正确答案: A解析: 暂无解析 -
第11题:
单选题查看系统当中所有进程的命令是()。Aps all
Bps aix
Cps auf
Dps aux
正确答案: D解析: 暂无解析 -
第12题:
单选题下面不属于Hadoop安装步骤的是()A安装JDK和配置Java环境变量
B设置免密码登录
C下载Eclipse集成开发环境
D修改Hadoop配置文件并启动Hadoop
正确答案: A解析: 暂无解析 -
第13题:
从后台启动进程,应在命令的结尾加上( )。
A、&
B、@
C、#
D、$
参考答案:A
-
第14题:
从后台启动进程,应在命令的结尾加上符号()?
- A、&
- B、@
- C、#
- D、$
正确答案:A -
第15题:
在ps命令什么参数是用来显示所有用户的进程的()。
- A、x
- B、b
- C、u
- D、a
正确答案:D -
第16题:
要在命令行上以后台方式启动进程,需要在执行的命令后添加()符号。
正确答案:& -
第17题:
从后台启动进程,应在命令的结尾加上符号&。
正确答案:正确 -
第18题:
启动进程有手动启动和调度启动两种方法,其中调度启动常用的命令为()、()和()。
正确答案:at;batch;crontab -
第19题:
显示系统中所有进程的命令是()。
- A、ps
- B、top
- C、process
- D、以上都不是
正确答案:A -
第20题:
单选题下面关于Hadoop兼容性错误的是()。AFlink能够支持Yarn,能够从HDFS和HBase中获取数据
B能够使用所有的Hadoop的格式化输入和输出
C能够使用Hadoop原有的Mappers和Reducers,但不能与Flink的操作混合使用
D能够更快的运行Hadoop的作业
正确答案: A解析: 暂无解析 -
第21题:
单选题显示系统中所有进程的命令是()。Aps
Btop
Cprocess
D以上都不是
正确答案: D解析: 暂无解析 -
第22题:
填空题启动进程有手动启动和调度启动两种方法,其中调度启动常用的命令为()、()和()。正确答案: at,batch,crontab解析: 暂无解析 -
第23题:
填空题要在命令行上以后台方式启动进程,需要在执行的命令后添加()符号。正确答案: &解析: 暂无解析 -
第24题:
单选题显示指定用户所启动的进程的命令是()。Aps-x
Bps-u
Cps-g
D以上都不是
正确答案: D解析: 暂无解析