
●试题三阅读下列函数说明和C函数,将应填入(n)处的字句写在答题纸的对应栏内。【函数3说明】函数DeleteNode(Bitree*r,int e)的功能是:在树根结点指针为r的二叉查找(排序)树上删除键值为e的结点,若删除成功,则函数返回0,否则函数返回-1。二叉查找树结点的类型定义为:typedef struct Tnode{int data;/*结点的键值*/struct Tnode*Lchild,*Rchild;/*指向左、右子树的指针*/}*Bitree;在二叉查找树上删除一个结点时,要考虑三种
题目
●试题三
阅读下列函数说明和C函数,将应填入(n)处的字句写在答题纸的对应栏内。
【函数3说明】
函数DeleteNode(Bitree*r,int e)的功能是:在树根结点指针为r的二叉查找(排序)树上删除键值为e的结点,若删除成功,则函数返回0,否则函数返回-1。二叉查找树结点的类型定义为:
typedef struct Tnode{
int data;/*结点的键值*/
struct Tnode*Lchild,*Rchild;/*指向左、右子树的指针*/
}*Bitree;
在二叉查找树上删除一个结点时,要考虑三种情况:
①若待删除的结点p是叶子结点,则直接删除该结点;
②若待删除的结点p只有一个子结点,则将这个子结点与待删除结点的父结点直接连接,然后删除结点p;
③若待删除的结点p有两个子结点,则在其左子树上,用中序遍历寻找关键值最大的结点s ,用结点s的值代替结点p的值,然后删除结点s,结点s必属于上述①、②情况之一。
【函数3】
int DeleteNode(Bitree*r,int e){
Bitree p=*r,pp,s,c;
while( (1) ){/*从树根结点出发查找键值为e的结点*/
pp=p;
if(e<p->data)p=p->Lchild;
else p=p->Rchild;
}
if(!p)return-1;/*查找失败*/
if(p->Lchild &&p->Rchild) { /*处理情况③*/
s= (2) ;pp=p;
while( (3) ){pp=s;s=s->Rchild;}
p->data=s->data;p=s;
}
/*处理情况①、②*/
if( (4) )c=p->Lchild;
else c=p->Rchild;
if(p==*r)*r=c;
else if( (5) )pp->Lchild=c;
else pp->Rchild=c;
free(p);
return 0;
}
相似考题
更多“●试题三阅读下列函数说明和C函数,将应填入(n)处的字句写在答题纸的对应栏内。【函数3说明】函数DeleteNode(Bitree*r,int e)的功能是:在树根结点指针为r的二叉查找(排序)树上删除键值为e的结点,若删除成功,则函数返回0,否则函数返回-1。二叉查找树结点的类型定义为:typedef struct Tnode{int data;/*结点的键值*/struct Tnode*Lchild,*Rchild;/*指向左、右子树的指针*/}*Bitree;在二叉查找树上删除一个结点时,要考虑三种”相关问题
-
第1题:
阅读下列函数说明和C函数,将应填入______处的语句写在答题纸的对应栏内。
[函数6说明]
函数DelA_InsB(LinkedList La,LinkedList Lb,int key1,int key2,int len)的功能是:将线性表A中关键码为key1的结点开始的len个结点,按原顺序移至线性表B中关键码为key2的结点之前,若移动成功,则返回0;否则返回-1。线性表的存储结构为带头结点的单链表,La为表A的头指针,Lb为表B的头指针。单链表结点的类型定义为:
typedef struct node {
int key;
struct node * next;
} * LinkedList;
[函数6]
int DelA InsB(LinkedList La,LinkedList Lb,int key1,int key2,int len)
{ LinkedListp,q,s,prep,pres;
int k;
if(! La->next‖! Lb->next‖->next‖len<=0)return-1;
p=La->next;prep=La;
while(p&&p->key!=key1){ / * 查找表A中键值为key1的结点 * /
prep=p;p=p->next;
}
if(! p)return -1; / * 表A中不存在键值为key1的结点 * /
q=p;k=1;
while(q&& (1) ){ / * 在表A中找出待删除的len个结点 * /
(2);k++;
}
if(! q)return-1: / * 表A中不存在要被删除的len个结点 * /
s=Lb->next; (3);
while(s s && s->key!=key2){ / * 查找表B中键值为key2的结点 * /
pres=s;s=s->next;
}
if(! s)return-1; / * 表B中不存在键值为key2的结点 * /
(4)=q->next; / * 将表A中的len个结点删除 * /
q->next=(5);
pres->next=p; / * 将len个结点移至表B * /
return 0;
}
正确答案:(1)klen (2)q=q->next (3)pres=Lb (4)prep->next (5)s或pres->next
(1)klen (2)q=q->next (3)pres=Lb (4)prep->next (5)s或pres->next 解析:本题是在链表插入和删除单个结点的基础上进行扩展,一次性插入多个结点和删除多个结点其原理和插入、删除一个结点的运算是一致的。首先在A链表中查找键值为key1的结点,使用了下列循环:
While(p&&p->key!=key1) {/ * 查找表A中键值为key1的结点 * /
Prep=p;p=p->next;
}因此,当找到键值为key1的结点时,p指向该结点,prep指向p的前驱。然后看在p的后面是否有len个结点,使用了下列语句:
q=p;k=1;
while(q&&(1)) {/ * 在表A中找出待删除的len个结点 * /
(2);k++;
}显然,首先把q指向p,k为计数器,所以该循环的结束条件有2个,一个是p的后面没有 len个结点,这时q为空,所以(2)空应填写q=q->next,使q的指针往后移动;另一个是 p的后面有len个结点,这时k=len。所以(1)空应填写klen。
根据上面的语句,如果p的后面有len个结点,则q指向第len个结点。如图2-2所示(虚线表示省略了中间若干个结点)。

同样,在表B中查找键值为key2的结点,使用了下列循环:
s=Lb->next;(3);
while(s&&s->key!=key2){/ * 查找表B中键值为key2的结点 * /
pres=s;s=s->next;
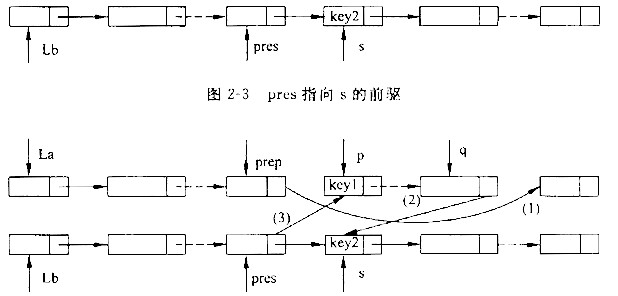
}首先,s指向第一个结点,然后进行循环,循环的结束条件也是2个,要么s为空(这时说明从头到尾都没有找到键值为key2的结点),要么找到了,s指向该结点,pres指向s的前驱。但是,如果第一个结点的键值就是key2的话,根据循环条件,循环中的语句不执行,则pres没有值,所以(3)空应该填写pres=Lb,使pres始终指向s的前驱。如图2-3所示 (虚线表示省略了中间若干个结点)。
最后将p到q的连续len个结点从A表中删除,在B表中插入,如图2-4所示。
程序中使用的语句如下:
(4)=q->next;/ * 将表A中的len个结点删除 * /
q->next=(5);
pres->next=p; / * 将len个结点移至表B * /
要把p到q的连续len个结点从A表中删除,就要把p的前驱(prep)的next指向q的next,因此,(4)空应填写prep->next。然后把q的next指向B表中s,把s的前驱 (pres)的next指向p,所以,(5)空应填写s。 -
第2题:
阅读下列C函数和函数说明,将应填入(n)处的字句写在对应栏内。
【说明】
函数DeleteNode (Bitree *r, int e)的功能是:在树根结点指针为r的二叉查找(排序)树上删除键值为e的结点,若删除成功,则函数返回0,否则函数返回-1。二叉查找树结点的类型定义为:
typedef struct Tnode{
int data; /*结点的键值*/
struct Tnode *Lchild, *Rchild; /*指向左、右子树的指针*/
}*Bitree:
在二叉查找树上删除一个结点时,要考虑3种情况:
①若待删除的结点p是叶子结点,则直接删除该结点;
②若待删除的结点p只有一个子结点,则将这个子结点与待删除结点的父结点直接连接,然后删除结点p;
③若待删除的结点p有两个子结点,则在其左子树上,用中序遍历寻找关键值最大的结点s,用结点s的值代替结点p的值,然后删除结点s,结点s必属于上述①、②情况之一。
【函数】
int DeleteNode (Bitree *r,int e) {
Bitree p=*r,pp,s,c;
while ( (1) ){ /*从树根结点出发查找键值为e的结点*/
pp=p;
if(e<p->data) p=p->Lchild;
else p=p->Rchild;
}
if(!P) return-1; /*查找失败*/
if(p->Lchild && p->Rchild) {/*处理情况③*/
s=(2);pp=p
while (3) {pp=s;s=s->Rchild;}
p->data=s->data; p=s;
}
/*处理情况①、②*/
if ( (4) ) c=p->Lchild;
else c=p->Rchild;
if(p==*r) *r=c;
else if ( (5) ) pp->Lchild=c;
else pp->Rchild=c;
free (p);
return 0;
}
正确答案:(1)p &&p->data!=e;或p!=NULL&&p->data!=e或p&&(*p).data!=e (2)p->Lchild或(*p).Lchild (3)p->Rchild或(*p).Rchild (4)p->Lchild或(*p).Lchild (5)pp->Lchid=p或p=(*pp).child
(1)p &&p->data!=e;或p!=NULL&&p->data!=e或p&&(*p).data!=e (2)p->Lchild或(*p).Lchild (3)p->Rchild或(*p).Rchild (4)p->Lchild或(*p).Lchild (5)pp->Lchid=p或p=(*pp).child 解析:本程序的功能是删除二叉查找树的一个结点。题目中对怎样删除结点有着比较详细的说明。
第1种情况就是删除叶子结点,叶子结点可以直接删除,这一点很好理解,因为叶子结点删除后并不会打乱查找树的顺序。
第2种情况是删除只有一个子结点的结点,只需把其子结点代替父结点即可。若子结点下有子树,子树结构不变。
第3种情况要复杂一点,要用到二叉查找树的一些性质,就是结点右子树的所有结点都大于根结点,左子树所有结点都小于根结点。所以,当删除了有左右子树的结点时,要在左子树找最大的结点,来替换被删结点。 -
第3题:
试题四
阅读下列函数说明和C函数,将应填入 (n) 处的字句写在答题纸的对应栏内。
[函数说明]
函数DeleteNode(Bitree *r,int e)的功能是:在树根结点指针为r的二叉查找(排序)树上删除键值为e的结点,若删除成功,则函数返回0,否则函数返回-1。二叉查找树结点的类型定义为:
typedef struct Tnode{
int data;
struct Tnode *Lchild,*Rchild;
}*Bitree;
在二叉查找树上删除一个结点时,要考虑三种情况:
1若待删除的结点p是叶子结点,则直接删除该结点;
2若待删除的结点p只有一个子结点,则将这个子结点与待删除结点的父结点直接连接,然后删除结点p;
3若待删除的结点p有两个子结点,则在其左子树上,用中序遍历寻找关键值最大的结点s,用结点s的值代替结点p的值,然后删除结点s,结点s必属于上述1、2情况之一。
[函数代码]
int DeleteNode(Bitree *r,int e) {
Bitreep = *r, pp, s, c;
while( (1) ) { /*从树根结点出发查找键值为e的结点*/
pp = p;
if ( e< p->data) p = p -> Lchild;
else p = p->Rchild;
}
if(!p) return –1; /* 查找失败 */
if(p->Lchild && p->Rchild) { /* 处理情况3 */
s = (2);pp = p;
while ( (3) ) { pp = s; s = s-> Rchild; }
p->data = s ->data; p = s;
}
/*处理情况1、2*/
if( (4) ) c = p -> Lchild;
elsec = p -> Rchild;
if(p == *r) *r = c;
elseif ( (5) ) pp -> Lchild = c;
elsepp->Rchild = c;
free(p);
return 0;
}
正确答案:试题分析:
本程序的功能是删除二叉查找树的一个结点。首先,我们来了解一下什么是二叉查找树。
二叉查找树,又称二叉排序树(BinarySort Tree)。一棵二叉查找树,或者是一棵空树,或者满足以下递归条件:
①查找树的左、右子树各是一棵查找树。
②若查找树的左子树非空,则其左子树上的各结点值均小于根结点的值。
③若查找树的右子树非空,则其右子树上的各结点值均大于根结点的值。
例如下图就是一棵二叉查找树。

了解二叉查找树的概念以后,我们再来看题目会有事半功倍的效果。题目中对怎样删除结点有着比较详细的说明。
第一种情况就是删除叶子结节,叶子结节可以直接删除,这一点很好理解,因为叶子结节删除后并不会打乱查找树的顺序。也就是说把上图中的“20”结点删除,剩下的还是一棵查找树。
第二种情况是删除只有一个子结点的结点,只需把其子结点代替父结点即可,也就是说若要删除图中的“56”结点,只需把“51”移至“56”位置即可,若“51”下有子树,子树结构不变。
第三种情况要复杂一点,要用到二叉查找树的一些性质,就是结点右子树的所有结点都大于根结节,左子树所有结点都小于根结点。所以,当删除了有左右子树的结点时,要在左子树找最大的结节,来替换被删结点。也就是说若要删除图中的”89”结点,要把“56”搬到“89”的位置。再用第二种情况规则,把“51”调整到原来56的位置。
现在我们已经了解了算法流程,可以开始具体的分析程序了。
第一句是变量的声明,以及赋初值,p指向二叉查找树的根。接下来是一个循环,从注释部分可以知道,此循环的功能是查找键值为e的结点。循环内有判断条件当e < p->data 时,进入左子树查找,否则到右子树中查找。很明显没有关于找到结点的处理代码,也就是说,循环内部只处理了没找到结点的情况,所以循环条件应是当找到键值为e的结点时退出循环,同时应注意一个隐含的限制条件,就是当p=NULL时,表示已经查找完毕,也不用进入循环了。所以(1)应填 p && p->data != e。
接下来的if 程序段是处理第 ③种情况的,由循环中的“s = s-> Rchild;”可以看出,s用于在要删结点的左子树中查找键值最大的结点。所以s的初值应是:要删除结点的左子结点。所以,(2)应填:p->Lchild。
结合前面提到的对第③条规则的描述以及二叉查找树的规则,我们可知,要找的结点s应是左子树最右的结点,即右子结点为NULL的结节。所以(3)应填S->Rchild。
再下来就是对①、②的处理了,这里并没有把①、②处理分开进行,而是合在一起进行处理,这里引入了一个中间变量c,用c来存储用于替换p的结点。
我们现在来分析一下,怎样的条件可以使这两种情况合在一起,因为当要删除的结点为叶子结点时,p->Lchild与p->Rchild都为NULL,当要删除的结点有一个子结点时,如果有左子结点,则p->Rchild为Null;如果有右子结点,则p->Lchild为NULL。所以当p->Lchild不为NULL时,说明是第二种情况,p结点含左子结点,所以c=p->Lchild,当p->Lchild为NULL时,说明有两种可能:第一,p->Rchild也为NULL,则p是叶子结点。第二,p->Rchild不为NULL,则p是有右子结点的结点。但这两种情况都可以用:c = p->Rchild,因为当p是叶子结点的时候用NULL代替p的位置即可。所以第(4)空,应填 p->Lchild。在程序中很多地方都出现了变量pp,其实只要仔细看一下前面的程序就知道,pp一直指向的是p结点的前一个结点,即p的父结点,所以(5)的作用是,判断p是其父结点的左子结点,还是右子结点,也就是说(5)应填 pp->Lchild == p。
参考答案:(每空3分)
(1)p && p->data != e 或者 p!=NULL && p->data != e
(2)p->Lchild
(3)s->Rchild
(4)p->Lchild
(5)pp->Lchild == p 或者 p == pp->Lchild
-
第4题:
阅读下列函举说明和C代码,将应填入(n)处的字句写在对应栏内。
【说明4.1】
假设两个队列共享一个循环向量空间(如图1-2所示),其类型Queue2定义如下:
typedef struct {
DateType data [MaxSize];
int front[2],rear[2];
}Queue2;
对于i=0或1,front[i]和rear[i]分别为第i个队列的头指针和尾指针。函数.EnQueue (Queue2*Q,int i,DaleType x)的功能是实现第i个队列的入队操作。
【函数4.1】
int EnQueue(Queue2 * Q, int i, DateType x)
{ /*若第i个队列不满,则元素x入队列,并返回1;否则,返回0*/
if(i<0‖i>1) return 0;
if(Q->rear[i]==Q->front[(1)]
return 0;
Q->data[(2)]=x;
Q->rear[i]=[(3)];
return 1;
}
【说明4.2】
函数BTreeEqual(BinTreeNode*T1,BinTtneNode*T2)的功能是递归法判断两棵二叉树是否相等,若相等则返回1,否则返回0。函数中参数T1和T2分别为指向这两棵二叉树根结点的指针。当两棵树的结构完全相同,并且对应结点的值也相同时,才被认为相等。
已知二叉树中的结点类型BinTreeNode定义为:
struct BinTreeNode {
char data;
BinTreeNode * left, * right;
};
其中dau为结点值域,leR和risht分别为指向左、右子女结点的指针域,
【函数4.2】
int BTreeEqual(BinTreeNode * T1, BinTreeNode * T2)
{
if(Ti == NULL && T2 == NULL)return 1 /*若两棵树均为空,则相等*/
else if((4))return 0; /*若一棵为空一棵不为空,则不等*/
else if((5)) return 1; /*若根结点值相等并且左、右子树*/
/*也相等,则两棵树相等,否则不等*/
else return 0;
}
正确答案:(1)(i+1)%2(或1-i) (2)Q->rear[i] (3)(Q->rear[i]++)%Maxsize (4)T1==NULL‖T2==NULL (5)T1->data==T2-> data && BTreeEqual(T1->leftT2->left) && BTreeEqual (T1->right T2->right)
(1)(i+1)%2(或1-i) (2)Q->rear[i] (3)(Q->rear[i]++)%Maxsize (4)T1==NULL‖T2==NULL (5)T1->data==T2-> data && BTreeEqual(T1->left,T2->left) && BTreeEqual (T1->right, T2->right) 解析:这一题共有两个函数,第一个函数是一个循环共享队列入队的的问题,第二个函数是用递归法判断两棵二叉树是否相等的问题。
先分析第一个函数。(1)空所在if语句是判断是否能入队,当队列0入队时,如果队列0队尾指针与队列1队头指针相等时,说明队列 0无法入队;当队列1入队时,如果队列1队尾指针与队列0队头指针相等时,说明队列1无法入队。因此(1)空处应填写“(i+1)%2”或“1-i”。(2)、(3)空是入队操作,其操作步骤是先将元素x插入队列i队尾所指的位置,再将队尾“加1”。因此(2)空处应填写“Q->rear[i]”;由于是一个循环队列,(3)空处应填写“(Q->rear[i]+1)%Maxsize”。
再分析第二个函数。这一题比较简单,只需将程序注释转换成C语言即可得到答案。(4)空所处理的是若一棵为空,而一棵不为空则不相等,显然(4)空应填入“TI==NULL‖T2==NULL”。(5)空处是一个递归调用,处理若根结点值相等并且左、右子树也相等,则两棵树相等,因此(5)空应填入“T1->data==T2->data && BTreeEqual(T1->left, T2->left) &&BTreeEqual(Tl->right, T2->right)”及其等价形式。 -
第5题:
阅读下列说明和c函数代码,将应填入 (n) 处的字句写在答题纸的对应栏内。
【说明】
对二叉树进行遍历是二叉树的一个基本运算。遍历是指按某种策略访问二叉树的每个结点,且每个结点仅访问一次的过程。函数InOrder。()借助栈实现二叉树的非递归中序遍历运算。
设二叉树采用二叉链表存储,结点类型定义如下:
typedef struct BtNode{
ElemTypedata; /*结点的数据域,ElemType的具体定义省略*/
struct BtNode*ichiid,*rchild; /*结点的左、右弦子指针域*/
)BtNode,*BTree;
在函数InOrder()中,用栈暂存二叉树中各个结点的指针,并将栈表示为不含头结点
的单向链表(简称链栈),其结点类型定义如下:
typedef struct StNode{ /*链栈的结点类型*/
BTree elem; /*栈中的元素是指向二叉链表结点的指针*/
struct StNode*link;
}S%Node;
假设从栈顶到栈底的元素为en、en-1、…、e1,则不含头结点的链栈示意图如图5—5
所示。

【C函数】
int InOrder(BTree root) /*实现二叉树的非递归中序遍历*/
{
BTree ptr; /*ptr用于指向二又树中的结点*/
StNode*q; /*q暂存链栈中新创建或待删除的结点指针+/
StNode*stacktop=NULL; /*初始化空栈的栈顶指针stacktop*/
ptr=root; /*ptr指向二叉树的根结点*/
while( (1 ) I I stacktop!=NULL){
while(ptr!=NULL){
q=(StNode*)malloc(sizeof(StNode));
if(q==NULL)
return-1;
q->elem=ptr;(2) ;
stacktop=q; /*stacktop指向新的栈顶*/
ptr=(3 ) ; /*进入左子树*/
}
q=stacktop; (4) ; /*栈顶元素出栈*/
visit(q); /*visit是访问结点的函数,其具体定义省略*/
ptr= (5) ; /*进入右子树*/
free(q); /*释放原栈顶元素的结点空间*/
}
return 0;
}/*InOrder*/
正确答案:(1)ptr! =NULL或ptr! =0或ptr(2)q->link=stacktop(3)ptr->lchild(4)stacktop=stacktop->link或stacktop=q->link(5)q->elem->rchild
(1)ptr! =NULL或ptr! =0或ptr(2)q->link=stacktop(3)ptr->lchild(4)stacktop=stacktop->link或stacktop=q->link(5)q->elem->rchild 解析:对非空二叉树进行中序遍历的方法是:先中序遍历根节点的左子树,然后访问根节点,最后中序遍历根节点的右子树。从以上算法的执行过程可知,从树根出发进行遍历时,递归调用InOrderTraversing(root-LeftChild)使得遍历过程沿着左孩子分支一直走向下层节点,直到到达二叉树中最左下方的节点(设为f)的空左子树为止,然后返回节点,再由递归调用InOrder Traversing(root->RightChild)进入f的右子树,并重复以上过程。在递归算法执行过程中,辅助实现递归调用和返回处理的控制栈实际上起着保存从根节点到当前节点的路径信息。用非递归算法实现二叉树的中序遍历时,可以由一个循环语句实现从指定的根节点m发,沿着左孩子分支一直到头(到达一个没有左子树的节点)的处理,从根节点到当前节点的路径信息(节点序列)可以明确构造一个栈来保存。 -
第6题:
阅读下列函数说明和C代码,将应填入(n) 处的字句写在对应栏内。
【说明】
函数print(BinTreeNode*t; DateType &x)的功能是在二叉树中查找值为x的结点,并打印该结点所有祖先结点。在此算法中,假设值为x的结点不多于一个。此算法采用后序的非递归遍历形式。因为退栈时需要区分右子树。函数中使用栈ST保存结点指针ptr以及标志tag,Top是栈顶指针。
【函数】
void print( BinTreeNode * t; DateType &x) {
stack ST; int i, top; top = 0;//置空栈
while(t! = NULL &&t-> data!= x || top!=0)
{ while(t!= NULL && t-> data!=x)
{
/*寻找值为x的结点*/
(1);
ST[top]. ptr = t;
ST[top]. tag = 0;
(2);
}
if(t!= Null && t -> data == x) { /*找到值为x的结点*/
for(i=1;(3);i ++)
printf("%d" ,ST[top]. ptr ->data);
else {
while((4))
top--;
if(top>0)
{
ST[top]. tag = 1;
(5);
}
}
}
正确答案:(1)top++ (2)t=t->leftChild (3)i=top (4)top>0 && ST[top].tag=1 (5)t=ST[top].ptr->rightChild
(1)top++ (2)t=t->leftChild (3)i=top (4)top>0 && ST[top].tag=1 (5)t=ST[top].ptr->rightChild 解析:这个程序是一个典型二叉树后序遍历非递归算法的应用。算法的实现思路是:先扫描根结点的所有左结点并入栈;当找到一个结点的值为x,则输入出栈里存放的数据,这些数据就是该结点所有祖先结点;然后判断栈顶元素的右子树是否已经被后序遍历过,如果是,或者右子树为空,将栈顶元素退栈,该子树已经全部后序遍历过;如果不是,则对栈顶结点的右子树进行后序遍历,此时应把栈顶结点的右子树的相结点放入栈中。再重复上述过程,直至遍历过树中所有结点。
(1)、(2)空年在循环就是扫描根结点的所有左结点并入栈,根据程序中的栈的定义,栈空时top=0,因此在入栈时,先将栈顶指针加1,因此(1)空处应填写“top++”或其等价形式,(2)空是取当前结点的左子树的根结点,因此应填写“t=t->leftChild”。
(3)空所在循环是处理找到值为x的结点,那么该结点的所有祖先结点都存放在栈中,栈中的栈底是二叉树的根,而栈顶元素是该结点的父结点,因此,(3)空处应填写“i=top”。
(4)空所在循环是判断栈顶元素的右子树是否已经被后序遍历过,如果是,或者右子树为空,将栈顶元素退栈,这里要填写判断条件。 tag=0表示左子树,tag=1表示右子树,因此,(4)空处应填写“top> 0&&ST [top].tag=1”。
(5)空所在语句块是处理栈顶元素的右子树没有被后序遍历情况,则将右子树入栈,因此(5)空处应填写“t=ST[top].ptr->rightChild”。 -
第7题:
阅读以下说明和C语言函数,将应填入(n)处的字句写在答题纸的对应栏内。
【说明】
一棵非空二叉树中“最左下”结点定义为:若树根的左子树为空,则树根为“最左下”结点;否则,从树根的左子树根出发,沿结点的左
子树分支向下查找,直到某个结点不存在左子树时为止,该结点即为此二叉树的“最左下”结点。例如,下图所示的以 A为根的二叉树的“最
左下”结点为D,以C为根的子二叉树中的“最左下”结点为C。
二叉树的结点类型定义如下:
typedef stmct BSTNode{
int data;
struct BSTNode*lch,*rch;//结点的左、右子树指针
}*BSTree;
函数BSTree Find Del(BSTree root)的功能是:若root指向一棵二叉树的根结点,则找出该结点的右子树上的“最左下”结点*p,并从
树于删除以*p为根的子树,函数返回被删除子树的根结点指针;若该树根的右子树上不存在“最左下”结点,则返回空指针。
【函数】
BSTrce Find_Del(BSTreeroot)
{ BSTreep,pre;
if ( !root ) return NULL; /*root指向的二叉树为空树*/
(1); /*令p指向根结点的右子树*/
if ( !p ) return NULL;
(2); /*设置pre的初值*/
while(p->lch){ /*查找“最左下”结点*/
pre=p;p=(3);
}
if ((4)==root) /*root的右子树根为“最左下”结点*/
pre->rch=NULL;
else
(5)=NULL; /*删除以“最左下”结点为根的子树*/
reurn p;
}
正确答案:(1)p=root->rch (2)pre=root (3)p->lch (4)pre (5)pre->lch
(1)p=root->rch (2)pre=root (3)p->lch (4)pre (5)pre->lch 解析:根据题目中的说明,函数BSTree FindDel (BSTreeroot)的功能是:若root指向一棵二叉树的根结点,则找出该结点的右子树上的“最
左下”结点*p,并从树中删除以 *p为根的子树,函数返回被删除子树的根结点指针;若该树根的右子树上不存在“最左下”结点,则返回空指
针。而一棵非空二叉树中“最左下”结点定义为:若树根的左子树为空,则树根为“最左下”结点;否则,从树根的左子树根出发,沿结点的
左子树分支向下查找,直到某个结点不存在左子树时为止,该结点即为此二叉树的“最左下”结点。
因此,给定一棵非空二叉树后,其右子树上的“最左下”结点要么为右子树根结点自己,要么为右子树根的左子树结点。
当二叉树非空时,root指向的结点是存在的,因此,令p指向根结点的右子树表示为“p=root->rch"。在二叉树上删除结点的操作实质上
是重置其父结点的某个子树指针,因此查找被删除结点时,需要保存被删结点的父结点指针,pre起的就是这个作用。空 (2)处应填入
“p=root",使得指针pre与p指向的结点始终保持父子关系。根据“最左下”结点的定义,空(3)处应填入“p->lch"。
当root的右子树根为“最左下”结点时,pre指针的指向就不会被修改,因此,空 (4)处应填入“pre”。若“最左下”结点在root的右子
树的左子树上,则删除以p指向的“最左下”结点为根的子树就是将pre(*p的父结点)的左子树指针置空,因此,空 (5)填入“pre->Ich"。 -
第8题:
阅读下列函数说明和C函数,将应填入(n)处的字句写在对应栏内。
[说明]
二叉树的二叉链表存储结构描述如下:
lypedef struct BiTNode
{ datatype data;
street BiTNode *lchiht, *rchild; /*左右孩子指针*/ } BiTNode, *BiTree;
下列函数基于上述存储结构,实现了二叉树的几项基本操作:
(1) BiTree Creale(elemtype x, BiTree lbt, BiTree rbt):建立并返回生成一棵以x为根结点的数据域值,以lbt和rbt为左右子树的二叉树;
(2) BiTree InsertL(BiTree bt, elemtype x, BiTree parent):在二叉树bt中结点parent的左子树插入结点数据元素x;
(3) BiTree DeleteL(BiTree bt, BiTree parent):在二叉树bt中删除结点parent的左子树,删除成功时返回根结点指针,否则返回空指针;
(4) frceAll(BiTree p):释放二叉树全体结点空间。
[函数]
BiTree Create(elemtype x, BiTree lbt, BiTree rbt) { BiTree p;
if ((p = (BiTNode *)malloc(sizeof(BiTNode)))= =NULL) return NULL;
p->data=x;
p->lchild=lbt;
p->rchild=rbt;
(1);
}
BiTree InsertL(BiTree bt, elemtype x,BiTree parent)
{ BiTree p;
if (parent= =NULL) return NULL;
if ((p=(BiTNode *)malloc(sizeof(BiTNode)))= =NULL) return NULL;
p->data=x;
p->lchild= (2);
p->rchild= (2);
if(parent->lchild= =NULL) (3);
else{
p->lchild=(4);
parent->lchild=p;
}
return bt;
}
BiTree DeleteL(BiTree bt, BiTree parent)
{ BiTree p;
if (parent= =NULL||parent->lchild= =NULL) return NULL;
p= parent->lchild;
parent->lchild=NULL;
freeAll((5));
return bt;
正确答案:(1) return p (2) NULL (3) parent->lchild=p (4) parent->lchild (5) p
(1) return p (2) NULL (3) parent->lchild=p (4) parent->lchild (5) p 解析:(1)此处应返回新建的二叉树;(2)新元素结点初始化时,数据域取值x,左右孩子指针指向NULL;
(3)若parent结点的左孩子结点空,则直接令其左孩子指针指向p;
(4)若parent结点的左孩子结点不空,则让新结点p充当其左子树的根;
(5)此处需释放二叉树p(parent的左子树)所占用的空间。 -
第9题:
阅读以下函数说明和C语言函数,将应填入(n)处的字句写在对应栏内。
[说明]
已知r[1...n]是n个记录的递增有序表,用折半查找法查找关键字为k的记录。若查找失败,则输出“failure",函数返回值为0;否则输出“success”,函数返回值为该记录的序号值。
[C函数]
int binary search(struct recordtype r[],int n,keytype k)
{ intmid,low=1,hig=n;
while(low<=hig){
mid=(1);
if(k<r[mid].key) (2);
else if(k==r[mid].key){
printf("succesS\n");
(3);
}
else (4);
}
printf("failure\n");
(5);
}
正确答案:(1) (low+hig)/2 (2) hig=mid-1 (3) returnmid (4) low=mid+1 (5) return 0
(1) (low+hig)/2 (2) hig=mid-1 (3) returnmid (4) low=mid+1 (5) return 0 解析:折半查找法也就是二分法:初始查找区间的下界为1,上界为len,查找区间的中界为k=(下界+上界)/2。所以(1)应填“(low+hig)/2”。中界对应的元素与要查找的关键字比较。当kr[mid].key时,(2)填“hig=mid-1”;当k==r[mid].key时,(3)填“return mid”;当k>r[mid].key时,(4)填“low=mid+1”。如果low>hig时循环终止时,仍未找到需查找的关键字,那么根据题意返回0,即空(5)填“return 0”。 -
第10题:
阅读以下说明和C代码,填补代码中的空缺,将解答填入答题纸的对应栏内。 【说明】 二叉查找树又称为二叉排序树,它或者是一棵空树,或者是具有如下性质的二叉树。 (1)若它的左子树非空,则左子树上所有结点的值均小于根结点的值。 (2)若它的右子树非空,则右子树上所有结点的值均大于根结点的值。 (3)左、右子树本身就是两棵二叉查找树。 二叉查找树是通过依次输入数据元素并把它们插入到二叉树的适当位置上构造起来的,具体的过程是:每读入一个元素,建立一个新结点,若二叉查找树非空,则将新结点的值与根结点的值相比较,如果小于根结点的值,则插入到左子树中,否则插入到右子树中;若二叉查找树为空,则新结点作为二叉查找树的根结点。 根据关键码序列{46,25,54,13,29,91}构造一个二叉查找树的过程如图4-1所示。
 设二叉查找树采用二叉链表存储,结点类型定义如下: typedef int KeyType; typedef struct BSTNode{ KeyType key; struct BSTNode *left,*right; }BSTNode,*BSTree; 图4-1(g)所示二叉查找树的二叉链表表示如图4-2所示。图4-2 函数int InsertBST(BSTree *rootptr,KeyType kword)功能是将关键码kword插入到由rootptr指示出根结点的二叉查找树中,若插入成功,函数返回1,否则返回0。
设二叉查找树采用二叉链表存储,结点类型定义如下: typedef int KeyType; typedef struct BSTNode{ KeyType key; struct BSTNode *left,*right; }BSTNode,*BSTree; 图4-1(g)所示二叉查找树的二叉链表表示如图4-2所示。图4-2 函数int InsertBST(BSTree *rootptr,KeyType kword)功能是将关键码kword插入到由rootptr指示出根结点的二叉查找树中,若插入成功,函数返回1,否则返回0。【C代码】 int lnsertBST(BSTree*rootptr,KeyType kword) /*在二叉查找树中插入一个键值为kword的结点,若插入成功返回1,否则返回0; *rootptr为二叉查找树根结点的指针 */ { BSTree p,father; (1) ; /*将father初始化为空指针*/ p=*rootptr; /*p指示二叉查找树的根节点*/ while(p&& (2) ){ /*在二叉查找树中查找键值kword的结点*/ father=p; if(kword<p->key) p=p->left; else p=p->right; } if( (3) )return 0; /*二叉查找树中已包含键值kword,插入失败*/ p=(BSTree)malloc( (4) ); /*创建新结点用来保存键值kword*/ If(!p)return 0; /*创建新结点失败*/ p->key=kword; p->left=NULL; p->right=NULL; If(!father) (5) =p; /*二叉查找树为空树时新结点作为树根插入*/ else if(kword<father->key) (6) ; /*作为左孩子结点插入*/ else (7) ; /*作右孩子结点插入*/ return 1; }/*InsertBST*/
正确答案:father=(void*)0
keyword!=p->key
p
sizeof(BSTNode)
*rootptr
father->left=p
father->right=p
-
第11题:
试题三(共15分)
阅读以下说明和C函数,填充函数中的空缺,将解答填入答题纸的对应栏内。
【说明】
函数Insert _key (*root,key)的功能是将键值key插入到*root指向根结点的二叉查找树中(二叉查找树为空时*root为空指针)。若给定的二叉查找树中已经包含键值为key的结点,则不进行插入操作并返回0;否则申请新结点、存入key的值并将新结点加入树中,返回l。
提示:
二叉查找树又称为二叉排序树,它或者是一棵空树,或者是具有如下性质的二叉树:
●若它的左子树非空,则其左子树上所有结点的键值均小于根结点的键值;
●若它的右子树非空,则其右子树上所有结点的键值均大于根结点的键值;
●左、右子树本身就是二叉查找树。
设二叉查找树采用二叉链表存储结构,链表结点类型定义如下:
typedef struct BiTnode{
int key _value; /*结点的键值,为非负整数*/
struct BiTnode *left,*right; /*结点的左、右子树指针*/
}BiTnode, *BSTree;
【C函数】
int Insert _key( BSTree *root,int key)
{
BiTnode *father= NULL,*p=*root, *s;
while( (1)&&key!=p->key_value){/*查找键值为key的结点*/
father=p;
if(key< p->key_value)p= (2) ; /*进入左子树*/
else p= (3) ; /木进入右子树*/
}
if (p) return 0; /*二叉查找树中已存在键值为key的结点,无需再插入*/
s= (BiTnode *)malloc( (4) );/*根据结点类型生成新结点*/
if (!s) return -1;
s->key_value= key; s->left= NULL; s->right= NULL;
if( !father)
(5) ; /*新结点作为二叉查找树的根结点*/
else /*新结点插入二叉查找树的适当位置*/
if( key< father->key_value)father->left = s;
elsefather->right = s;
retum 1:
}
正确答案:
(1)p
(2)p->left
(3) p->right
(4) sizeof(BiTnode)
(5) *root=s
-
第12题:
阅读以下说明和C代码,填补代码中的空缺,将解答填入答题纸的对应栏内。【说明】二叉查找树又称为二叉排序树,它或者是一棵空树,或者是具有如下性质的二叉树。(1)若它的左子树非空,则左子树上所有结点的值均小于根结点的值。(2)若它的右子树非空,则右子树上所有结点的值均大于根结点的值。(3)左、右子树本身就是两棵二叉查找树。二叉查找树是通过依次输入数据元素并把它们插入到二叉树的适当位置上构造起来的,具体的过程是:每读入一个元素,建立一个新结点,若二叉查找树非空,则将新结点的值与根结点的值相比较,如果小于根结点的值,则插入到左子树中,否则插入到右子树中;若二叉查找树为空,则新结点作为二叉查找树的根结点。根据关键码序列{46,25,54,13,29,91}构造一个二叉查找树的过程如图4-1所示。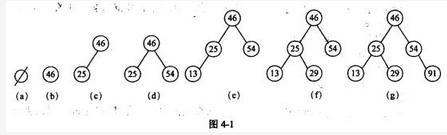
设二叉查找树采用二叉链表存储,结点类型定义如下:
typedef int KeyType;typedef struct BSTNode{KeyType key;struct BSTNode *left,*right;}BSTNode,*BSTree;
图4-1(g)所示二叉查找树的二叉链表表示如图4-2所示。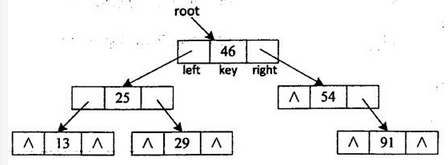
函数int InsertBST(BSTree *rootptr,KeyType kword)功能是将关键码kword插入到由rootptr指示出根结点的二叉查找树中,若插入成功,函数返回1,否则返回0。【C代码】
int lnsertBST(BSTree*rootptr,KeyType kword)/*在二叉查找树中插入一个键值为kword的结点,若插入成功返回1,否则返回0;*rootptr为二叉查找树根结点的指针*/{BSTree p,father;(1) /*将father初始化为空指针*/p=*rootptr; /*p指示二叉查找树的根节点*/while(p&&(2)){ /*在二叉查找树中查找键值kword的结点*/father=p;if(kword<p->key)p=p->left;elsep=p->right;}if((3))return 0; /*二叉查找树中已包含键值kword,插入失败*/ p=(BSTree)malloc((4)); /*创建新结点用来保存键值kword*/If(!p)return 0; /*创建新结点失败*/p->key=kword;p->left=NULL;p->right=NULL; If(!father)(5) =p; /*二叉查找树为空树时新结点作为树根插入*/elseif(kword<father->key)(6);/*作为左孩子结点插入*/else(7);/*作右孩子结点插入*/return 1;}/*InsertBST*/答案:解析:father=(void*)0keyword!=p-keypsizeof(BSTNode)*rootptrfather-left=pfather-right=p -
第13题:
阅读以下说明和C语言函数,将应填入(n)处。
[说明]
二叉排序树或者是一棵空树,或者是具有如下性质的二叉树:若它的左子树非空,则左子树上所有结点的值均小于根结点的值;若它的右子树非空,则右子树上所有结点的值均大于根结点的值;左、右子树本身就是两棵二义排序树。
函数insert_BST(char *str)的功能是:对给定的字符序列按照ASCⅡ码值大小关系创建二叉排序树,并返回指向树根结点的指针。序列中重复出现的字符只建一个结点,并由结点中的Count域对字符的重复次数进行计数。
二叉排序树的链表结点类型定义如下:
typedef struct BSTNode{
char Elem; /*结点的字符数据*/
int Count; /*记录当前字符在序列中重复出现的次数*/
struct BSTNode *Lch,*Rch; /*接点的左、右子树指针*/
}*BiTree;
[函数]
BiTree insert_BST(char *str)
{ BiTree root,parent,p;
char (1); /*变量定义及初始化 */
root=(BiTree)malloc(sizeof(struct BSTNode));
if(!root||*s=='\0') return NULL;
root->Lch=root->Rch=NULL; foot->Count=1; root->Elem=*s++;
for(; *s!='\0';s++) {
(2); parent=NULL;
while (p){ /*p从树跟结点出发查找当前字符*s所在结点 */
parent = p;
if(*s==p->Elem)/*若树中已存在当前字符结点,则当前字符的计数值加1*/
{p->Count++; break;}
else /*否则根据字符*s与结点*p中字符的关系,进入*p的左子树或右子树*/
if (*s>p->Elem) p=p->Rch;
else p=p->Lch;
}/*while*/
if( (3)) {/* 若树中不存在字符值为*s的结点,则申请结点并插入树中 */
p=(BiTree)malloc(sizeof(struct BSTNode));
if(!p)return NULL;
p->Lch=p->Rch=NULL; p->Count=1; p->Elem=*s;
/*根据当前字符与其父结点字符值的大小关系,将新结点作为左子树或右子树插入*/
if(p->Elem>parent->Elem) (4)=p;
else (5)=p;
}
}/*for*/
return root;
}
正确答案:(1) *s=str(2) p=root(3) p==NULL (4) parent->Rch(5) parent->Lch
(1) *s=str(2) p=root(3) p==NULL (4) parent->Rch(5) parent->Lch 解析:本题考查二叉排序树在链表存储结构上的运算。
函数insert_BST(char *str)的功能是对给定的字符序列str按照ASCⅡ码值大小关系创建二叉排序树,并返回指向树根结点的指针,序列中重复出现的字符只建一个结点,并由结点中的Count域对字符的重复次数进行计数。
根据程序代码中对字符序列中字符的引用情况,可知需要在空(1)处定义字符指针s,其初值应为参数str的值。for语句的作用是对序列中的每个字符*s,用while循环从树根结点出发查找*s所在结点。由于while的条件p为非空指针时循环,因此此前应设置 p的初值,显然空(2)是为p没初值root,从而对每个字符*s都可以从树根出发,开始查找结点。若树中已存在当前字符*s的结点,则*s字符的计数值加1,并结束对该字符的查找过程,若树中不存在*s的结点,则会进入树的一个空子树(以p为空表示),因此空(3)处应填入“p==NULL”或“中!p”。
插入新的结点时,需要建立其与父结点的关系,在查找结点的过程中parent表示待插入结点的父结点。因此根据二叉排序树的定义,待插入元素的值大于其父结点的值,则作为右子结点插入,否则作为左子结点插入。所以,空(4)、(5)分别填入parent->Rch和parent->Lch。 -
第14题:
阅读下列函数说明和C函数,将应填入(n)处的字句写在对应栏内。
【说明】
函数DeleteNode(Bitree*r,inte)的功能是:在树根节点指针为r的二叉查找(排序)树上删除键值为e的节点,若删除成功,则函数返回0,否则函数返回-1。二叉查找树节点的类型定义为:
typedef struct Tnode{
int data;/*节点的键值*/
struct Tnode *Lchild,*Rchiid;/*指向左、右子树的指针*/
}*Bitree;
在二叉查找树上删除一个节点时,要考虑3种情况。
①若待删除的节点p是叶子节点,则直接删除该节点。
②若待删除的节点p只有一个子节点,则将这个子节点与待删除节点的父节点直接连接,然后删除节点。
③若待删除的节点p有两个子节点,则在其左子树上,用中序遍历寻找关键值最大的节点 s,用节点s的值代替节点p的值,然后删除节点s,节点s必属于上述①、②情况之一。
【函数5-5】
int DeleteNode(Bitree *r,int e){
Bitree p=*r,pp,s,c;
while( (1) {/*从树根节点出发查找键值为e的节点*/
pp=p;
if(e<p->data)p=p->Lchild;
else p=p->Rehild;
}
if(!p)retrn -1;/*查找失败*/
if(p->Lchild && p->Rchild){/*处理情况③*/
s=(2); pp=p;
while( (3)){pp=s;s=s->Rchild;}
p->data=s->data;p=s;
}
/* 处理情况①、②*/
if((4))c=p->Lchild;
else c=p->Rchild;
if(p== *r)*r=c;
else if((5))pp->Lchild=c;
else pp->Rchild=c;
free(p);
return 0;
}
正确答案:(1) p&&p->data!=e或p&&(*p).data!=e (2) p->Lchild或(*p).Lchild (3) s->Rchild或(*s).Rchild (4) p->Lchild或(*p).Lchild (5) p==pp->Lchild或p==(*pp).Lchild
(1) p&&p->data!=e或p&&(*p).data!=e (2) p->Lchild或(*p).Lchild (3) s->Rchild或(*s).Rchild (4) p->Lchild或(*p).Lchild (5) p==pp->Lchild或p==(*pp).Lchild 解析:本题考查二叉查找树上的删除操作,题中已清楚说明了删除操作的算法。
删除一个节点首先需要进行查找,只有找到了欲删除的节点才谈得上删除。程序首先让指针p指向根节点,通过while循环进行查找。循环体内,先用pp记录p,这样pp最终将记录p的父节点,然后如果得删关键字e小于当前节点p的键字值,则p赋值为p->Lchild,即往左子树继续查找,否则,p赋值为p->Rchild,即往右子树继续查找。显然,循环体内并未处理关键字正好等于当前节点p的键值的情况,因此该条件应体现在while循环的终止条件中。故空(1)应填“p&&p->data!=e”。
空(2)比较简单。此处是处理情况③,而根据算法描述,情况③要在左子树中寻找键值最大的节点,亦即左子树中最右的节点(右节点为NULL),并保存在s中。故空(2)应填 p->Lchild。空(3)所在while循环正是用来在p的左子树中查找右节点为NULL的节点的,故空(3)应填s->Rchild。
接下来处理情况①和情况②,这两种情况本身是比较简单的,但在此将两者合并在一起处理,增加了难度。首先用变量c来存储用来替换p的节点,然后分情况将c正确插入。
当要删除的节点为叶节点时(情况①),其p->Lchild和p->Rchild均为NULL;当要删除的节点只有一个子节点时(情况②),若仅有左子节点,则p->Rchild为NULL,若仅有右子节点,则p->Lchild为NULL。所以当p->Lchild不为NULL时,说明是情况②:仅有左节点情况,故c=p->Lchild。当p->Lchild为NULL时,则有两种可能:p->Rchild也为NULL,则对应情况①叶节点情况;p->Rchild不为NULL,则对应情况②仅有右节点情况。但这两种情况下,亦可以统一采用c=p->Rchild,因为当p是叶节点时用NULL代替其位置即可。所以空(4)应填“p->Lchild!=NULL”。
接下来就要将c正确插入到原二叉树中。上面已经提到,pp指向的是p节点的父节点。因此若p是pp的左节点,则将c作为pp的左子节点插入,因此空(5)应填“p==pp->Lchild”。 -
第15题:
阅读下列函数说明和C函数,将应填入(n)处的字句写在对应栏内。
【说明】
函数DelA_InsB(LinkedList La,LinkedList Lb,int key1,int key2,int len)的功能是:将线性表A中关键码为key1的结点开始的len个结点,按原顺序移至线性表B中关键码为key2的结点之前,若移动成功,则返回0;否则返回-1。线性表的存储结构为带头结点的单链表,La为表A的头指针,Lb为表B的头指针。单链表结点的类型定义为
typedef struct node {
int key;
struct node * next;
} *LinkedList;
【函数】
int DelA_InsB ( LinkedList La, LinkdeList Lb,int key1,int key2,,int len)
{ LinkedList p,q,s,prep,pres;
int k;
if( ! La->next || ! Lb-> next ||| en <=0)return-1;
p = La -> next;prep = La;
while(p&&p- >key != key1) { /*查找表A中键值为key1的结点*/
prep = p;p = p -> next;
}
if( ! p) return - 1; /*在表A中不存在键值为key1的结点*/
q=p;k=1;
while(q &&(1))} /*表A中不存在要被删除的len个结点*/
(2);k++;
}
if( ! q)return -1; /*表A中不存在要被删除的len个结点*/
s = Lb -> next;(3);
while(s && s -> key != key2) { /*查找表B中键值为key2的结点*/
pres =s;s =s->next;
}
if( ! s) return - t; /*表B中不存在键值为key2的结点*/
(4)=q-> next; /*将表A中的len个结点删除*/
q->next=(5);
pres -> next = p; /*将len个结点移至表B */
return 0;
}
正确答案:(1)klen (2)q=q->next或q=(*q).next (3)pres=Lb (4)prep->next或(*prep).next (5)s或pres->next或(*pres).next
(1)klen (2)q=q->next或q=(*q).next (3)pres=Lb (4)prep->next或(*prep).next (5)s或pres->next或(*pres).next 解析:(1)此处while循环应当循环至k等于len结束,所以应填入klen。(2)此处语句表示链表前进一个结点,应填入q=q->next或q=(*q).next。(3)此处语句为指针pres赋初值,使他指向s的上一结点。(4)修改指针prep,使prep指向q的下一结点。(5)此处语句为修改指针q,q指向s或者pres的下一结点,达到将A中的len个结点删除的目的。 -
第16题:
阅读下列函数说明和C函数,将应填入(n)处。
【函数3说明】
函数DeleteNode(Bitree * r,int e)的功能是:在树根结点指针为r的二叉查找(排序)树上删除键值为e的结点,若删除成功,则函数返回0,否则函数返回-1。二叉查找树结点的类型定义为:
typedef struct Tnode{
int data; /*结点的键值*/
struct Tnode * Lchild,*Rchild; /*指向左、右子树的指针*/
} * Bitree;
在二叉查找树上删除一个结点时,要考虑三种情况:
①若待删除的结点p是叶子结点,则直接删除该结点;
②若待删除的结点p只有一个子结点,则将这个子结点与待删除结点的父结点直接连接,然后删除结点P;
③若待删除的结点p有两个子结点,则在其左子树上,用中序遍历寻找关键值最大的结点s,用结点s的值代替结点p的值,然后删除结点s,结点s必属于上述①、②情况之一。
【函数3】
int DeleteNode(Bitree * r,int e){
Bitree p=*r,pp,s,c;
while((1)){ /*从树根结点出发查找键值为e的结点*/
pp=p;
if(e<p->data)p=p->Lchild;
else p=p->Rchild;
{
if(!p)return-1; /*查找失败*/
if(p->Lchild &&p->Rchild){/*处理情况③*/
s=(2); pp=p;
while((3)){pp=s;s=s->Rchild;}
p->data=s->data;p=s;
}
/*处理情况①、②*/
if((4))c=p->Lchild;
else c=p->Rchild;
if(p==*r)*r=c;
else if((5))pp->Lchild=c;
else pp->Rchild=c;
free(p);
return 0;
}
正确答案:(1)p&&p->data!=e或p&&(*p).data!=e(2)p ->Lchild或(*p).Lchild (3)s->Rchild或(*s).Rchild(4)p->Lchild或 (*p).Lchild(5)p==pp->Lchild或p(*pp).Lchild
(1)p&&p->data!=e或p&&(*p).data!=e(2)p ->Lchild或(*p).Lchild (3)s->Rchild或(*s).Rchild(4)p->Lchild或 (*p).Lchild(5)p==pp->Lchild或p(*pp).Lchild 解析:(1)程序的第一条语句是变量的声明及赋初值,p指向二叉查找树的根。接下来从while循环的注释部分可以看出,该循环的功能是查找键值为e的结点。当循环的判断条件ep->data时,进入左子树查找,否则到右子树查找。程序中没有关于找到结点的处理代码,即循环内部只处理了没找到结点的情况,所以循环条件应该是当找到键值为e的结点时退出循环。另外,应注意一个隐含的限制条件“p’ NULL”时,表示已经查找完毕,无需进入循环。通过分析,(1)应填p &&p->data!=e。(2)if程序段是处理第三种情况的,由循环中的语句“s=s->Rchild;”可看出,s用于要删结点的左子树中查找键值最大的结点,所以s的初值应是要删除结点的左子结点。可见,(2)应填写 p->Lchild。(3)根据前面所述的二叉树规则可知,要找的结点s应是左子树中查找键值最大的结点,所以,的初值应是要删除结点的左子结点。可见,(3)应填p->Rehild。本题把①、②结合在一起进行处理,所以引入了一个中间变量c,用c来存储用于替换p的结点。现在的关键问题是什么条件可以使这两种情况和在一起,因为若删除的结点为叶子结点时,p->Rchild与p->Lchild都为NULL;若删除的结点有一个子结点时,如果有左子结点,则p->Rchild为p->Rchild;如果有右子结点,则p->Lchild为NULL。当p->Lchild不为NULL时,说明是第二种情况,p结点含左子结点,所以c=p->Lchild;当p->Lchild为 NULL时,说明有两种可能:
第一:p->Rchild也为NULL,则p是叶子结点。
第二:p->Rchild不为NULL,则p是有右子结点的结点。
这两种情况都可以用c=p->Rchild,因为当p是叶子结点的时候用NULL代替p的位置即可,所以第(4)应填p->Lehild。在程序中很多地方都出现了变量pp,其实只要仔细看一下前面的程序就知道,pp一直指向的是p结点的前一个结点,即p的父结点,所以(5)的作用是判断p是其父结点的左子结点还是右子结点,(5)应填pp->Lchild =p。 -
第17题:
阅读以下说明和C语言函数,将应填入(n)处的字句写在对应栏内。
[说明]
完成以下中序线索化二叉树的算法。
[函数]
Typedef int datatype;
Typedef struct node {
Int ltag, rtag;
Datatype data;
*lchild,* rchild;
}bithptr;
bithptr pre;
void inthread ( p );
{if
{inthread ( p->lchild );
if ( p->lchild==unll ) (1);
if ( P->RCHILD=NULL) p->rtag=1;
if (2)
{if (3) pre->rchild=p;
if ( p->1tag==1 )(4);
}
INTHREAD ( P->RCHILD );
(5);
}
}
正确答案:(1) P->LTAG=0 (2) (PRE) (3) (PRE->RTAG==1) (4) P->LCHILD=PRE (5) PRE=P
(1) P->LTAG=0 (2) (PRE) (3) (PRE->RTAG==1) (4) P->LCHILD=PRE (5) PRE=P -
第18题:
阅读以下函数说明和C语言函数,将应填入(n)处的字句写在对应栏内。
[说明]
已知一棵二叉树用二叉链表存储,t指向根结点,p指向树中任一结点。下列算法为输出从t到P之间路径上的结点。
[C程序]
define Maxsize 1000
typedef struct node{
TelemType data;
struct node*1child,*rchild;
}BiNode,*BiTree;
void Path(BiTree t,BiNode*P)
{ BiTree*stack[Maxsize],*stackl[Maxsize],*q;
int tag[Maxsize],top=0,topl;
q=t;
/*通过先序遍历发现P*/
do(while(q!=NULL && q!=p)
/*扫描左孩子,且相应的结点不为P*/
{ (1);
stack[top]=q;
tag[top]=0;
(2);
}
if(top>0)
{ if(stack[top]==P) break; /*找到P,栈底到栈顶为t到P*/
if(tag[top]==1)top--;
else{q=stack[top];
q=q->rchild;
tag[top]=1;
}
}
} (3);
top--; topl=0;
while(top>0){
q=stack[top]; /*反向打印准备*/
topl++;
(4);
top--;
}
while((5)){ /*打印栈的内容*/
q=stackl[topl];
printf(q->data);
topl--;
}
}
正确答案:(1) top++ (2) q=q->1child (3) while(top>0) (4) stackl[top1]=q (5) top1>0
(1) top++ (2) q=q->1child (3) while(top>0) (4) stackl[top1]=q (5) top1>0 解析:本题本质上是对二叉树的先序遍历进行考核,但不是简单地进行先序遍历,而是仅遍历从根结点到给定的结点p为止。本题采用非递归算法来实现,其主要思想是:①初始化栈:②根结点进栈,栈不空则循环执行以下步骤直到发现结点p;③当前结点不为空且不为P进栈;④栈顶为p,则结束,否则转③;⑤若右子树访问过,则栈顶的右孩子为当前结点,转③。
扫描左孩子,当相应的结点不为P时进栈,所以(1)填“top++”,(2)填“q=q->1child”。在栈不为空时则一直在do while循环中查找,因此(3)填“while(top>0)”。在进行反向打印准备时,读取stack[top]的信息放到stackl[top]中,即(4)填“stackl[top1]=q”。打印栈中所有内容,所以(5)填“top1>0”。 -
第19题:
阅读下列函数说明和C函数,将应填入(n)处的字句写对应栏内。
[说明]
二叉树的二叉链表存储结构描述如下:
typedef struct BiTNode
{ datatype data;
struct BiTNode *lchild, * rchild; /*左右孩子指针*/
}BiTNode,* BiTree;
对二叉树进行层次遍历时,可设置一个队列结构,遍历从二叉树的根结点开始,首先将根结点指针入队列,然后从队首取出一个元素,执行下面两个操作:
(1) 访问该元素所指结点;
(2) 若该元素所指结点的左、右孩子结点非空,则将该元素所指结点的左孩子指针和右孩子指针顺序入队。
此过程不断进行,当队列为空时,二叉树的层次遍历结束。
下面的函数实现了这一遍历算法,其中Visit(datatype a)函数实现了对结点数据域的访问,数组queue[MAXNODE]用以实现队列的功能,变量front和rear分别表示当前队首元素和队尾元素在数组中的位置。
[函数]
void LevelOrder(BiTree bt) /*层次遍历二叉树bt*/
{ BiTree Queue[MAXNODE];
int front,rear;
if(bt= =NULL)return;
front=-1;
rear=0;
queue[rear]=(1);
while(front (2) ){
(3);
Visit(queue[front]->data); /*访问队首结点的数据域*/
if(queue[front]—>lchild!:NULL)
{ rear++;
queue[rear]=(4);
}
if(queue[front]->rchild! =NULL)
{ rear++;
queue[rear]=(5);
}
}
}
正确答案:(1) bt (2) ! =rear (3) front+ + (4) queue [front]->lchild (5) queue[front]->rchild
(1) bt (2) ! =rear (3) front+ + (4) queue [front]->lchild (5) queue[front]->rchild 解析:(1)遍历开始时队列长度为1,其中只存放了根结点bt;
(2)遍历过程是一个循环访问队列的过程,其终止条件是队列为空,即front等于rear;
(3)遍历到某结点时,该结点应退出队列,因此队首元素的位置应该增1;
(4)此处应将队首结点的左孩子结点放入队列,即插在队尾;
(5)此处应将队首结点的右孩子结点放入队列,即插在队尾。 -
第20题:
阅读以下说明、C函数和问题,将解答填入答题纸的对应栏内。
【说明】
二叉查找树又称为二叉排序树,它或者是一棵空树,或者是具有如下性质的二叉树:
●若它的左子树非空,则其左子树上所有结点的键值均小于根结点的键值;
●若它的右子树非空,则其右子树上所有结点的键值均大于根结点的键值;
●左、右子树本身就是二叉查找树。
设二叉查找树采用二叉链表存储结构,链表结点类型定义如下:
typedefstructBiTnode{
intkey_value;/*结点的键值,为非负整数*/
structBiTnode*left,*right;/*结点的左、右子树指针*/
}*BSTree;
函数find_key(root,key)的功能是用递归方式在给定的二叉查找树(root指向根结点)中查找键值为key的结点并返回结点的指针;若找不到,则返回空指针。
【函数】
BSTreefind_key(BSTreeroot,intkey)
{
if((1))
returnNULL;
else
if(key==root->key_value)
return(2);
elseif(keykey_value)
return(3);
else
return(4);
}
【问题1】
请将函数find_key中应填入(1)~(4)处的字句写在答题纸的对应栏内。
【问题2】
若某二叉查找树中有n个结点,则查找一个给定关键字时,需要比较的结点个数取决于(5).
答案:
(1)!root,或root=0,或root==NULL
(2)root
(3)find_key(root→left,key)
(4)find_key(root→right,key)
(5)该关键字对应结点在该二叉查找树所在层次(数)或位置,或者该二叉树中从根结点到该关键字对应结点的路径长度
解析:
本题考查数据结构的应用、指针和递归程序设计。
根据二叉查找树的定义,在一棵二叉查找树上进行查找时,首先用给定的关键字与树根结点的关键字比较,若相等,则查找成功;若给定的关键字小于树根结点的关键字,则接下来到左子树上进行查找,否则接下来到右子树上进行查找。如果在给定的二叉查找树上不存在与给定关键字相同的结点,则必然进入某结点的空的子树时结束查找。因此,空(1)处填入"!root"表明进入了空树;空(2)处填入"root"表明返回结点的指针;空(3)处填入"find_key(root→left,key)"表明下一步到左子树上继续查找;空(4)处填入"find_key(root→right,key)"表明下一步到右子树上继续查找。
显然,在二叉排序树上进行查找时,若成功,则查找过程是走了一条从根结点到达所找结点的路径。例如,在下图所示的二叉排序树中查找62,则依次与46、54、101和62作了比较。因此,在树中查找一个关键字时,需要比较的结点个数取决于该关键字对应结点在该二叉查找树所在层次(数)或位置。
-
第21题:
阅读以下说明和 C 代码,填补代码中的空缺,将解答填入答题纸的对应栏内。 【说明】 函数 GetListElemPtr(LinkList L,int i)的功能是查找含头结点单链表的第i个元素。若找到,则返回指向该结点的指针,否则返回空指针。 函数DelListElem(LinkList L,int i,ElemType *e) 的功能是删除含头结点单链表的第 i个元素结点,若成功则返回 SUCCESS ,并由参数e 带回被删除元素的值,否则返回ERROR 。 例如,某含头结点单链表 L 如图 4-1 (a) 所示,删除第 3 个元素结点后的单链表如 图 4-1 (b) 所示。
 图4-1
图4-1define SUCCESS 0 define ERROR -1 typedef int Status; typedef int ElemType; 链表的结点类型定义如下: typedef struct Node{ ElemType data; struct Node *next; }Node ,*LinkList; 【C 代码】 LinkList GetListElemPtr(LinkList L ,int i) { /* L是含头结点的单链表的头指针,在该单链表中查找第i个元素结点: 若找到,则返回该元素结点的指针,否则返回NULL */ LinkList p; int k; /*用于元素结点计数*/ if (i<1 ∣∣ !L ∣∣ !L->next) return NULL; k = 1; P = L->next; / *令p指向第1个元素所在结点*/ while (p && (1) ) { /*查找第i个元素所在结点*/ (2) ; ++k; } return p; } Status DelListElem(LinkList L ,int i ,ElemType *e) { /*在含头结点的单链表L中,删除第i个元素,并由e带回其值*/ LinkList p,q; /*令p指向第i个元素的前驱结点*/ if (i==1) (3) ; else p = GetListElemPtr(L ,i-1); if (!p ∣∣ !p->next) return ERROR; /*不存在第i个元素*/ q = (4) ; /*令q指向待删除的结点*/ p->next = q->next; /*从链表中删除结点*/ (5) ; /*通过参数e带回被删除结点的数据*/ free(q); return SUCCESS; }
正确答案:(1) k<i
(2) p = p->next
(3) p=L
(4) p->next
(5) *e = q->data
-
第22题:
●试题一
阅读下列说明和流程图,将应填入(n)的语句写在答题纸的对应栏内。
【流程图说明】
下面的流程(如图1所示)用N-S盒图形式描述了在一棵二叉树排序中查找元素的过程,节点有3个成员:data,left和right。其查找的方法是:首先与树的根节点的元素值进行比较:若相等则找到,返回此结点的地址;若要查找的元素小于根节点的元素值,则指针指向此结点的左子树,继续查找;若要查找的元素大于根节点的元素值,则指针指向此结点的右子树,继续查找。直到指针为空,表示此树中不存在所要查找的元素。
【算法说明】
【流程图】
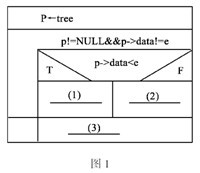
将上题的排序二叉树中查找元素的过程用递归的方法实现。其中NODE是自定义类型:
typedef struct node{
int data;
struct node*left;
struct node*right;
}NODE;
【算法】
NODE*SearchSortTree(NODE*tree,int e)
{
if(tree!=NULL)
{
if(tree->data<e)
(4) ;∥小于查找左子树
else if(tree->data<e)
(5) ;∥大于查找左子树
else return tree;
}
return tree;
}
正确答案:
●试题一【答案】(1)p=p->left(2)ptr=p->right(3)returnP(4)returnSearchSortTree(tree->left)(5)returnSearchSortTree(tree->right)【解析】所谓二叉排序树,指的是一棵为空的二叉树,或者是一棵具有如下特性的非空二叉树:①若它的左子树非空,则左子树上所有结点的值均小于根结点的值。②若它的右子树非空,则右子树上所有结点的值均大于根结点的值。③左、右子树本身又各是一棵二叉排序树。先来分析流程图。在流程图中只使用一个变量p,并作为循环变量来控制循环,所以循环体中必须修改这个值。当进入循环时,首先判断p是不是为空和该结点是不是要找的结点,如果这两个条件有一个满足就退出循环,返回prt,(如果是空,则返回NULL,说明查询失败;否则返回键值所在结点的指针。)因此(3)空处应当填写"returnp"。如果两个条件都不满足,就用查找键值e与当前结点的关键字进行比较,小的话,将指针p指向左子树继续查找,大的话将指针p指向右子树继续查找。于是,(1)空处应当填写"p=p->left",(2)空处应当填写"p=p->right"。再来分析程序。虽然是递归算法,但实现思路和非递归是一样。首先用查找键值e与树根结点的关键字比较,如果值小的话,就在左子树中查找(即返回在左子树中查找结果);如果值大的话在右子树中查找(即返回在右子树中查找结果);如果相等的话就返回树根指针。因此(4)、(5)空分别应填写"returnSearchSortTree(tree->left)"和"returnSearchSortTree(tree->right)"。 -
第23题:
阅读以下说明和C代码,填补代码中的空缺,将解答填入答题纸的对应栏内。
[说明]
函数GetListElemPtr(LinkList L,int i)的功能是查找含头结点单链表的第i个元素。若找到,则返回指向该结点的指针,否则返回空指针。
函数DelListElem(LinkList L,int i,ElemType *e)的功能是删除含头结点单链表的第i个元素结点,若成功则返回SUCCESS,并由参数e带回被删除元素的值,否则返回ERROR。
例如,某含头结点单链表L如下图(a)所示,删除第3个元素结点后的单链表如下图(b)所示。
1.jpg
#define SUCCESS 0 #define ERROR -1 typedef intStatus; typedef intElemType;
链表的结点类型定义如下:
typedef struct Node{ ElemType data; struct Node *next; }Node,*LinkList; [C代码] LinkListGetListElemPtr(LinkList L,int i) { /*L是含头结点的单链表的头指针,在该单链表中查找第i个元素结点; 若找到,则返回该元素结点的指针,否则返回NULL */ LinkList p; int k; /*用于元素结点计数*/ if(i<1 || !L || !L->next) return NULL; k=1; p=L->next; /*令p指向第1个元素所在结点*/ while(p &&______){ /*查找第i个元素所在结点*/ ______; ++k; } return p; } StatusDelListElem(LinkList L,int i,ElemType *e) { /*在含头结点的单链表L中,删除第i个元素,并由e带回其值*/ LinkList p,q; /*令P指向第i个元素的前驱结点*/ if(i==1) ______; else p=GetListElemPtr(L,i-1); if(!P || !p->next) return ERROR; /*不存在第i个元素*/ q=______; /*令q指向待删除的结点*/ p->next=q->next; //从链表中删除结点*/ ______; /*通过参数e带回被删除结点的数据*/ free(q); return SUCCESS; }答案:解析:k<i
p=p->next
p=L
p->next
*e=q->data
【解析】
本题考查C语言的指针应用和运算逻辑。
本问题的图和代码中的注释可提供完成操作的主要信息,在充分理解链表概念的基础上填充空缺的代码。
函数GetListElemPtr(LinkList L,int i)的功能是在L为头指针的链表中查找第i个元素,若找到,则返回指向该结点的指针,否则返回空指针。描述查找过程的代码如下,其中k用于对元素结点进行计数。
k=1; p=L->next; /*令p指向第1个元素所在结点*/