
已知两个链表A和B分别表示两个集合,其元素递增排列。请设计算法求出A与B的交集,并存放于A链表中。
题目
已知两个链表A和B分别表示两个集合,其元素递增排列。请设计算法求出A与B的交集,并存放于A链表中。
相似考题
参考答案和解析
参考答案:
只有同时出现在两集合中的元素才出现在结果表中,合并后的新表使用头指针Lc指向。pa和pb分别是链表La和Lb的工作指针,初始化为相应链表的第一个结点,从第一个结点开始进行比较,当两个链表La和Lb均为到达表尾结点时,如果两个表中相等的元素时,摘取La表中的元素,删除Lb表中的元素;如果其中一个表中的元素较小时,删除此表中较小的元素,此表的工作指针后移。当链表La和Lb有一个到达表尾结点,为空时,依次删除另一个非空表中的所有元素。
[算法描述]
void Mix(LinkList& La, LinkList& Lb, LinkList& Lc)
{ pa=La->next;pb=Lb->next;
pa和pb分别是链表La和Lb的工作指针,初始化为相应链表的第一个结点
Lc=pc=La; //用La的头结点作为Lc的头结点
while(pa&&pb)
{ if(pa->data==pb->data)∥交集并入结果表中。
{ pc->next=pa;pc=pa;pa=pa->next;
u=pb;pb=pb->next; delete u;}
else if(pa->datadata) {u=pa;pa=pa->next; delete u;}
else {u=pb; pb=pb->next; delete u;}
}
while(pa) {u=pa; pa=pa->next; delete u;}∥ 释放结点空间
while(pb) {u=pb; pb=pb->next; delete u;}∥释放结点空间
pc->next=null;∥置链表尾标记。
delete Lb; //释放Lb的头结点
}
只有同时出现在两集合中的元素才出现在结果表中,合并后的新表使用头指针Lc指向。pa和pb分别是链表La和Lb的工作指针,初始化为相应链表的第一个结点,从第一个结点开始进行比较,当两个链表La和Lb均为到达表尾结点时,如果两个表中相等的元素时,摘取La表中的元素,删除Lb表中的元素;如果其中一个表中的元素较小时,删除此表中较小的元素,此表的工作指针后移。当链表La和Lb有一个到达表尾结点,为空时,依次删除另一个非空表中的所有元素。
[算法描述]
void Mix(LinkList& La, LinkList& Lb, LinkList& Lc)
{ pa=La->next;pb=Lb->next;
pa和pb分别是链表La和Lb的工作指针,初始化为相应链表的第一个结点
Lc=pc=La; //用La的头结点作为Lc的头结点
while(pa&&pb)
{ if(pa->data==pb->data)∥交集并入结果表中。
{ pc->next=pa;pc=pa;pa=pa->next;
u=pb;pb=pb->next; delete u;}
else if(pa->data
else {u=pb; pb=pb->next; delete u;}
}
while(pa) {u=pa; pa=pa->next; delete u;}∥ 释放结点空间
while(pb) {u=pb; pb=pb->next; delete u;}∥释放结点空间
pc->next=null;∥置链表尾标记。
delete Lb; //释放Lb的头结点
}
更多“已知两个链表A和B分别表示两个集合,其元素递增排列。请设计算法求出A与B的交集,并存放于A链表中。 ”相关问题
-
第1题:
阅读以下说明和流程图,填补流程图中的空缺,将解答填入答题纸的对应栏内。
[说明]
两个包含有限个元素的非空集合A、B的相似度定义为|A∩B|/|A∪B|,即它们的交集大小(元素个数)与并集大小之比。
以下的流程图计算两个非空整数集合(以数组表示)的交集和并集,并计算其相似度。已知整数组A[1:m]和B[1:n]分别存储了集合A和B的元素(每个集合中包含的元素各不相同),其交集存放于数组C[1:s],并集存放于数组D[1:t],集合A和B的相似度存放于SIM。
例如,假设A={1,2,3,4},B={1,4,5,6},则C={1,4),D={1,2,3,4,5,6},A与B的相似度SIM=1/3。
[流程图]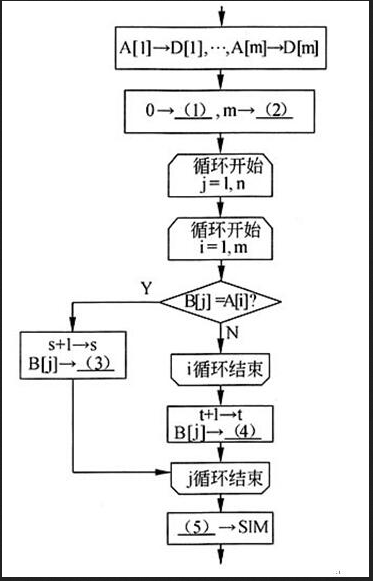 答案:解析:s
答案:解析:s
t
C[s]
D[t]
s/t
【解析】
本题考查程序处理流程图的设计能力。
首先我们来理解两个有限集合的相似度的含义。两个包含有限个元素的非空集合A、B的相似度定义为它们的交集大小(元素个数)与并集大小之比。如果两集合完全相等,则相似度必然为1(100%);如果两集合完全不同(没有公共元素),则相似度必然为0;如果集合A中有一半元素就是集合B的全部元素,而另一半元素不属于集合B,则这两个集合的相似度为0.5(50%)。因此,这个定义符合人们的常理性认识。
在大数据应用中,经常要将很多有限集进行分类。例如,每天都有大量的新闻稿。为了方便用户检索,需要将新闻稿分类。用什么标准来分类呢?每一篇新闻稿可以用其中所有的关键词来表征。这些关键词的集合称为这篇新闻稿的特征向量。两篇新闻稿是否属于同一类,依赖于它们的关键词集合是否具有较高的相似度(公共关键词个数除以总关键词个数)。搜索引擎可以将相似度超过一定水平的新闻稿作为同一类。从而,可以将每天的新闻稿进行分类,就可以按用户的需要将某些类的新闻稿推送给相关的用户。
本题中的集合用整数组表示,因此,需要规定同一数组中的元素各不相同(集合中的元素是各不相同的)。题中,整数组A[1:m]和B[1:n]分别存储了集合A和B的元素。流程图的目标是将A、B中相同的元素存放入数组C[1:s](共s个元素),并将A、B中的所有元素(相同元素只取一次)存放入数组D[1:t](共t个元素),最后再计算集合A和B相似度s/t。
流程图中的第一步显然是将数组A中的全部元素放入数组D中。随后,只需要对数组B中的每个元素进行判断,凡与数组A中某个元素相同时,就将其存入数组C;否则就续存入数组D(注意,数组D中已有m个元素)。这需要对j(遍历数组B)与i(遍历数组A)进行两重循环。判断框B[j]=A[i]成立时,B[j]应存入数组C;否则应继续i循环,直到循环结束仍没有相等情况出现时,就应将B[i]存入数组D。存入数组C之前,需要将其下标s增1;存入数组D之前,需要将其下标t增1。因此,初始时,应当给i赋0,使数组C的存数从C[1]开始。从而,(1)处应填s,(3)处应填C[s]。而数组D是在已有m个元素后续存,所以,初始时,数组D的下标t应当是m,续存是从D[m+1]开始的。因此,(2)处应填t,(4)处应填D[t]。
两重循环结束后,就要计算相似度s/t,将其赋予SIM,因此(5)处应填s/t。 -
第2题:
已知一个带有表头结点的非空单链表,结点结构为: data link 假设该链表中data域中存放的是整数,且只给出了头指针list,在不改变链表的前提下,请设计一个尽可能高效的算法,输出链表中所有间隔为k(k为正整数)的两个结点元素的和。要求: (1)给出算法的基本设计思想(3分) (2)根据设计思想,采用类C语言描述算法,关键之处给出简要注释。(7分)
对 -
第3题:
1、有两个递增有序表,所有元素为整数,均采用带头结点的单链表存储,结点类型定义如下: typedef struct node { int data; struct node *next; } LinkNode; 设计一个尽可能高效的算法,将两个递增有序单链表ha、hb合并为一个递减有序单链表hc,要求算法空间复杂度为O(1)。
A -
第4题:
用带头节点单链表表示集合,假设该单链表中的元素递增有序,设计一个高效算法求两个集合的交集,并分析该算法的时间和空间复杂度。
链头 -
第5题:
【论述题】假设有两个按元素值非递减次序排列的线性表,均以单链表形式存储。请编写算法将这两个单链表归并为一个按元素值非递增次序排列的单链表,并要求利用原来两个单链表的结点存放归并后的单链表。
错